
 Duolingo Research
Duolingo Research
Science powers our mission to make language education free and accessible to everyone.
Science powers our mission to make language education free and accessible to everyone.
With more than 500 million learners, Duolingo has the world's largest collection of language-learning data at its fingertips. This allows us to build unique systems, uncover new insights about the nature of language and learning, and apply existing theories at scales never before seen. We are also committed to sharing publications and data with the broader research community.
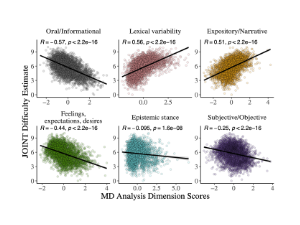
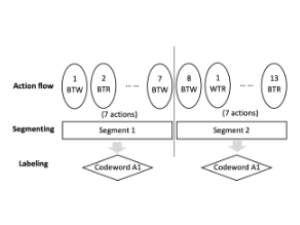
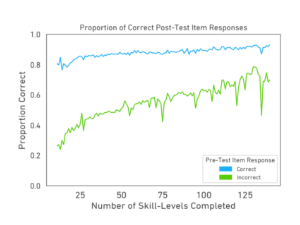
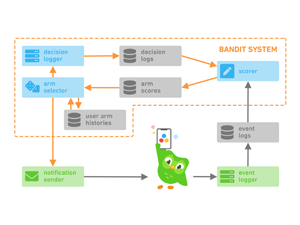
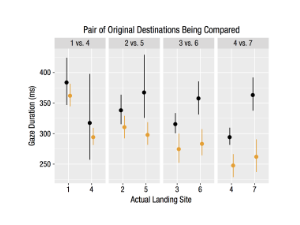
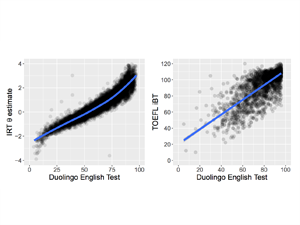
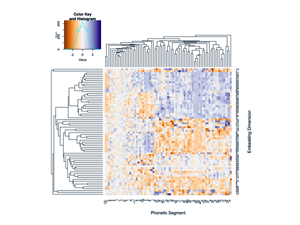

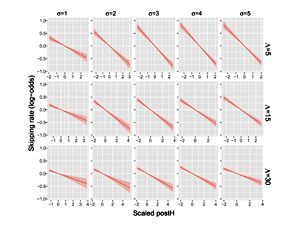

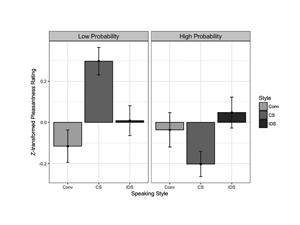
Replication data for our KDD 2020 paper, "A Sleeping, Recovering Bandit Algorithm for Optimizing Recurring Notifications." Includes 200 million examples of Duolingo practice reminder push notifications sent to Duolingo users over a 35 day period, including which template was used, whether the user converted within 2 hours, and other metadata.
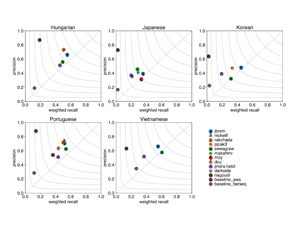
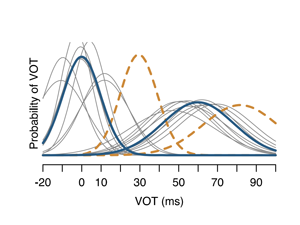
Data for the 2020 Shared Task on Simultaneous Translation And Paraphrase for Language Education (STAPLE). This corpus contains more than 3 million pairs of English sentences with multiple possible translations into Portuguese, Hungarian, Japanese, Korean, and Vietnamese.
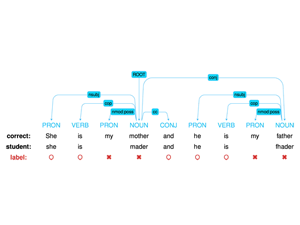
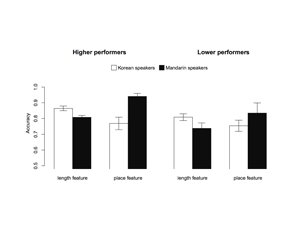
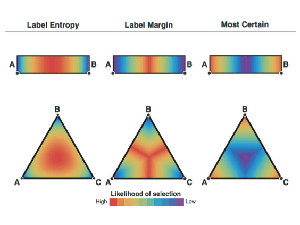
Data for the 2018 Shared Task on Second Language Acquisition Modeling (SLAM). This corpus contains 7 million words produced by learners of English, Spanish, and French. It includes user demographics, morph-syntactic metadata, response times, and longitudinal errors for 6k+ users over 30 days.
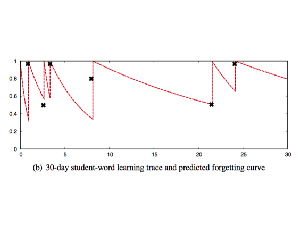
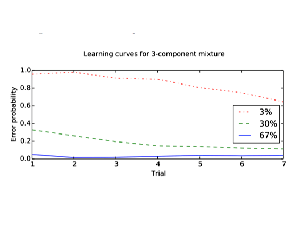
Data used to develop our half-life regression (HLR) spaced repetition algorithm. This is a collection of 13 million user-word pairs for learners of several languages with a variety of language backgrounds. It includes practice recall rates, lag times between practices, and other morpho-lexical metadata.
We are a diverse team of experts in AI and machine learning, data science, learning sciences, UX research, linguistics, and psychometrics. We work closely with product teams to build innovative features based on world-class research. We are growing, so check out our job openings below!











































Develop ML-driven technologies for novel applications in language, learning, and assessment that are used by millions of people every day.
Support data-driven product decisions and generate insights to guide product development for millions of learners worldwide.
Help improve how millions of people learn languages on Duolingo.

